
실시간 위치 데이터, 인스턴스마다 다르게 보이던 이유와 해결 과정
이번 포스트에서는 기존 서비스의 맵에서 실시간 택시 광고 디바이스 위치 데이터 기능을 고도화하는 과정에서 겪은 문제와 해결 과정을 공유하려 합니다.
서비스 환경에서는 실시간으로 송출 중인 택시 광고 디바이스(이하 미디어)의 위치를 시각화해야 했습니다.
이전 MVP에서는 AWS Lambda API를 통해 클라이언트가 주기적으로 Polling 요청을 보내는 방식으로 데이터를 전달했습니다.
하지만 Polling 방식은 실시간성이 부족하고, 미디어 수가 늘어날수록 요청과 응답의 크기가 커져 네트워크 부하와 응답 지연이 발생될거라 예상되었습니다.
이를 개선하기 위해 서버가 클라이언트에 한 번의 연결로 지속적으로 데이터를 푸시하는 SSE(Server-Sent Events) 방식으로 전환했습니다.
문제점
초기 설계는 “Kafka에서 미디어 위치 메시지를 컨슘하고, SSE로 클라이언트에게 전송하자”는 단순한 구조였습니다.
하지만 실제 운영 환경에서는 다음과 같은 문제가 있었습니다.
-
Kafka Consumer Group 구조
인스턴스가 확장되면 여러 인스턴스가 서로 다른 파티션을 컨슘하게 되어,
미디어 위치 데이터의 순서를 보장하기 어렵고 각 인스턴스 간 데이터 불일치가 발생했습니다. -
SSE의 인스턴스 메모리 관리 구조
각 인스턴스가 자체 메모리에SseEmitter를 저장하기 때문에,
전체 실시간 데이터를 제공하려면 여러 인스턴스의 데이터를 취합해야 하는 한계가 있었습니다.
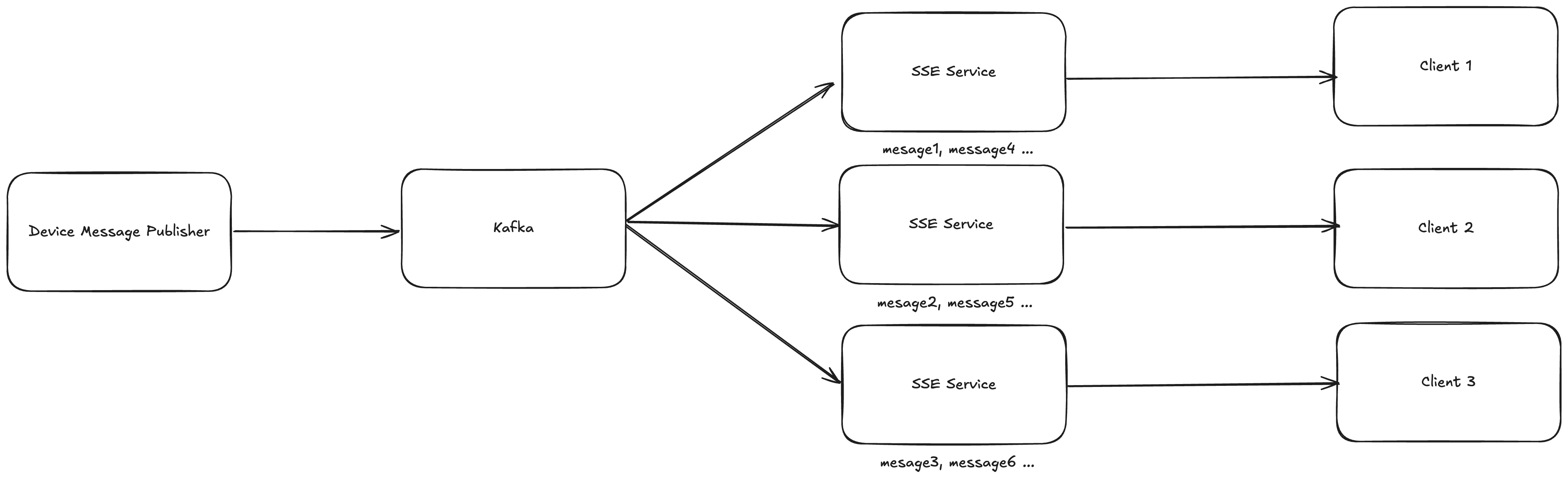
System Diagram
이 문제를 해결하기 위해 여러 방식을 검토했습니다.
해결 시나리오
SseEmitter를 단일 저장소(Redis)에 저장하고, 모든 인스턴스가 해당 저장소를 통해 데이터를 전송한다.- 각 인스턴스가 데이터를 DB에 저장하고, 시간순으로 정렬하여 조회 후 전달한다.
- 각 인스턴스가 컨슘한 데이터를 모든 인스턴스에 브로드캐스팅하여 취합 후 전달한다.
1) SseEmitter를 단일 저장소(Redis)에 저장
가장 단순하게 떠올린 방법이었습니다.
각 인스턴스의 SseEmitter를 Redis 같은 단일 저장소에 저장하고, 모든 인스턴스가 거기서 꺼내 동일한 방식으로 데이터를 전송하면 인스턴스 간 취합 없이 공통 경로로 보낼 수 있을 것이라 기대했습니다.
하지만 두 가지 이유로 이 방식은 사용하기 어렵다고 판단했습니다.
-
이벤트 순서 뒤섞임
여러 인스턴스가 같은 구독자에 대해 동시에 전송을 시도하면, 네트워크/스레드 스케줄링 타이밍에 따라 이벤트 순서가 섞이거나 중복 전송이 발생할 수 있습니다. 단일 저장소가 있더라도 송신 주체가 여러 개면 순서 제어가 복잡해집니다. -
SseEmitter는 직렬화 불가
SseEmitter는 클라이언트와의 HTTP 연결 상태(소켓, 응답 스트림 등)와 Servlet Container 레벨 리소스에 의존합니다. 이 객체를 외부 저장소에 직렬화/역직렬화하여 공유하는 것은 불가능합니다. 운영체제 및 컨테이너가 관리하는 커넥션 상태는 자바 직렬화로 이전할 수 있는 범위를 벗어납니다.

시스템 레벨 리소스는 직렬화할 수 없음 (Object Serialization: FAQ)
정리하면, SseEmitter 자체를 중앙 저장소에 담아 공유하는 설계는 기술적으로 성립하지 않고, 설령 유사 구조를 만든다 해도 송신 주체가 여러 개라 순서 보장이 어려워 최종적으로 제외했습니다.
2) 데이터를 DB에 저장 후 시간순으로 조회
이 방법은 영속화가 불필요한 실시간 데이터에는 적합하지 않습니다. 만약 구현한다면 다음과 같은 문제를 고려해야 합니다.
- 어느 시점까지 데이터를 조회할지 기준이 모호하다.
- 중복 조회를 방지하기 위한 오프셋 관리가 필요하다.
- 지속적인 데이터 적재로 인해 DB I/O 부하가 크고, 조회 시 매번 쿼리 I/O가 발생한다.
- Master/Slave 구조에서는 복제 지연으로 인해 실시간성이 떨어질 수 있다.
3) 각 인스턴스 간 데이터 브로드캐스팅
이 방법은 각 인스턴스가 컨슘한 데이터를 다른 인스턴스에게 전파하는 방식입니다.
각 인스턴스는 자신이 받은 데이터를 전파하고, 수신한 데이터를 자체적으로 취합해 연결된 클라이언트에게 전달합니다.
다만 다음 두 가지 문제가 있습니다.
- 데이터를 모든 인스턴스에 어떻게 전달할 것인가?
- 전달된 데이터의 순서를 어떻게 보장할 것인가?
이 두 문제를 해결하면 데이터를 저장하지 않고도 빠르게 취합 및 전송이 가능하다고 판단했습니다.
결과적으로 이 접근 방식을 채택했습니다.
(1) 데이터를 모든 인스턴스에 어떻게 전달할 것인가?
각 인스턴스가 수집한 미디어 데이터를 취합해야 했기에, 저장소를 거치지 않고 데이터를 전파할 수 있는 방법을 고민했습니다.
이 과정에서 Redis Pub/Sub을 선택했습니다.
Redis Pub/Sub은 Kafka와 달리 메시지를 기록하지 않고, 저장하지 않은 채 즉시 전달합니다.
또한 클라이언트의 수신 여부를 확인하지 않기 때문에 at-most-once(최대 한 번) 전달 보장을 따르며, 특정 채널을 구독 중인 모든 클라이언트에게 브로드캐스트 방식으로 메시지를 전송합니다.
즉, 네트워크 지연이나 연결 문제로 메시지가 유실될 수 있지만, 대신 가볍고 빠르게 데이터를 모든 인스턴스에게 전달할 수 있습니다.
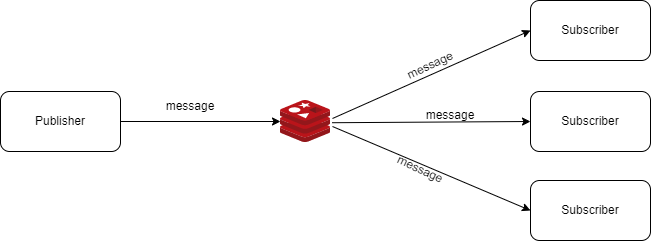
Redis Pub/Sub 구조
다음은 Redis Pub/Sub을 사용하기 위한 기본 설정 흐름입니다.
@Configuration
class RedisConfig {
@Bean
fun redisConnectionFactory(): RedisConnectionFactory {
return RedissonConnectionFactory(redissonClient(RedisProperties()))
}
@Bean
fun listenerContainer(
liveMediaCreativeMessageListener: MessageListener
): RedisMessageListenerContainer {
return RedisMessageListenerContainer().apply {
addMessageListener(liveMediaCreativeMessageListener, ChannelTopic(LIVE_MEDIA_LOCATIONS_TOPIC))
setConnectionFactory(redisConnectionFactory())
setTaskExecutor(redisSubTaskExecutor())
setErrorHandler { e -> logger.error("redis sub error... {}", e.message) }
setRecoveryInterval(Duration.ofSeconds(5).toMillis())
}
}
@Bean
fun redisSubTaskExecutor(): TaskExecutor {
return ThreadPoolTaskExecutor().apply {
this.corePoolSize = 4
this.maxPoolSize = 8
this.queueCapacity = 1000
setThreadNamePrefix("redis-sub-")
this.initialize()
}
}
}
@Component
class LiveDeviceMessageRedisListener(
private val messageService: LiveDeviceService
): MessageListener {
override fun onMessage(message: Message, pattern: ByteArray?) {
// 메시지 처리 로직
}
}
listenerContainer는 Redis Pub/Sub 메시지를 수신하기 위한 리스너 컨테이너로,
하나 이상의 MessageListener를 등록해 Redis 채널에서 전달된 메시지를 비동기적으로 처리할 수 있도록 구성합니다.
이 컨테이너는 내부적으로 RedisConnectionFactory를 통해 Redis 서버에 SUBSCRIBE 명령을 실행하고,
해당 채널에서 발행된 메시지를 수신한 뒤 등록된 MessageListener에게 전달합니다.
즉, Redis 구독 관리와 메시지 전달을 모두 담당하는 핵심 컴포넌트입니다.
이때 listenerContainer에 주입되는 MessageListener는
토픽을 구독하고 실제 메시지를 처리하는 인터페이스입니다.
개발자가 이를 구현한 클래스를 작성해 컨테이너에 등록하면, Redis에서 메시지가 발행될 때마다 해당 클래스의 onMessage() 메서드가 호출되어 메시지를 처리하게 됩니다.
또한 listenerContainer는 TaskExecutor를 사용해 수신된 메시지를 처리할 스레드풀을 관리합니다.
이 덕분에 Redis의 구독 스레드가 블로킹되지 않고, 메시지 수신과 처리 로직이 서로 독립적으로 동작할 수 있습니다.
정리하자면,
- RedisMessageListenerContainer → Redis 구독 관리 및 메시지 전달 담당
- MessageListener → 수신된 메시지 처리 담당
- TaskExecutor → 메시지 처리용 스레드풀 관리
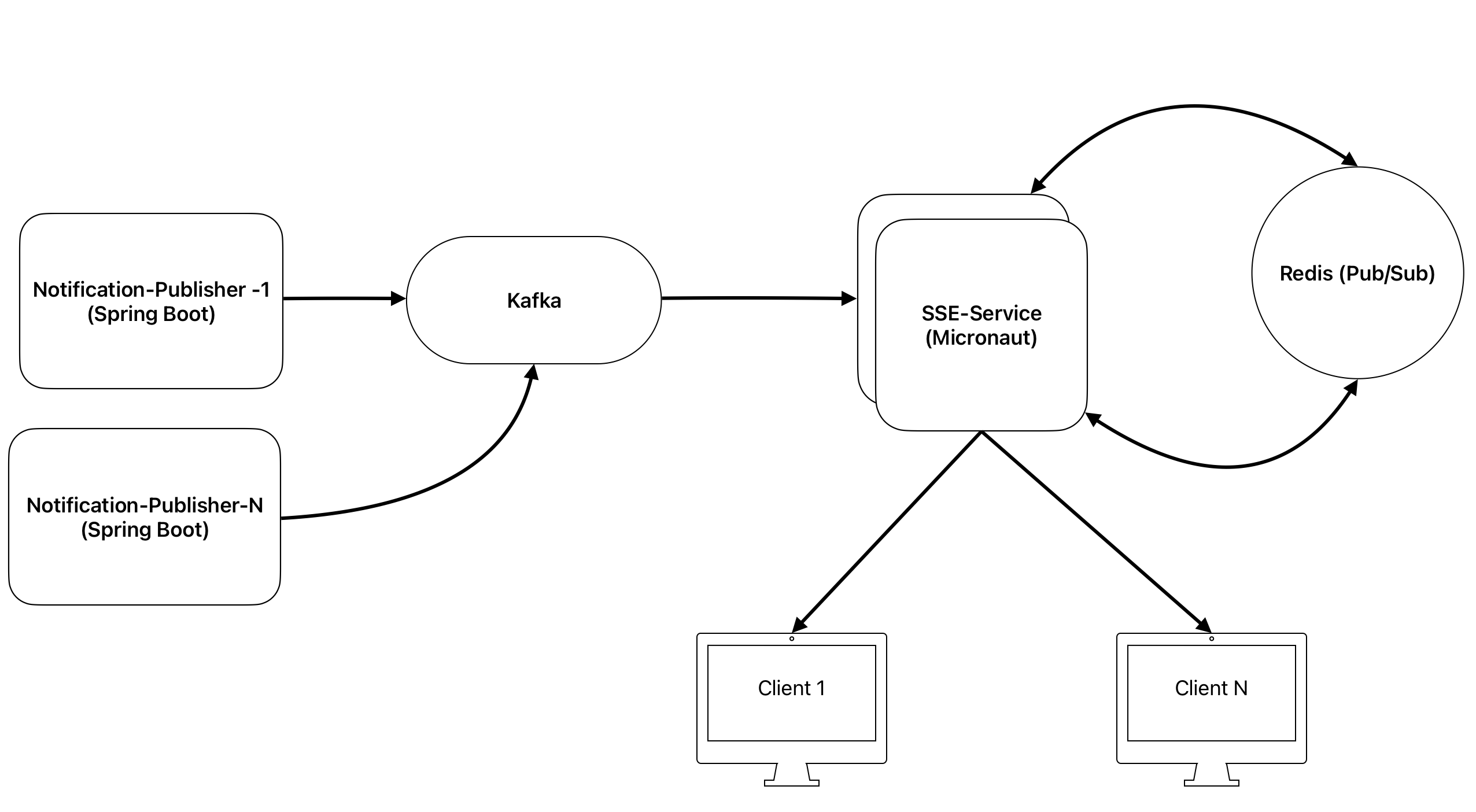
Kafka and Redis Broadcasting
이를 통해 각 인스턴스는 Kafka에서 받은 위치 데이터를 Redis Pub/Sub 토픽으로 발행(Publish)하고,
다른 인스턴스는 해당 토픽을 구독(Subscribe)하여 이벤트를 수신함으로써 모든 인스턴스가 동일한 실시간 데이터를 공유할 수 있습니다.
이 구조를 통해 각 인스턴스는 서로 데이터를 주고받으며,
각자의 메모리에 있는 SseEmitter를 통해 클라이언트에게 동일한 실시간 위치 데이터를 전달할 수 있게 되었습니다.
(2) 메시지 정렬 문제
Kafka → Redis Pub/Sub을 통해 모든 인스턴스가 동일한 메시지를 수신하게 되었지만, 여전히 메시지 순서 보장 문제가 남았습니다.
실시간 위치 데이터는 순서가 뒤섞이면 잘못된 위치나 시간 역전 현상이 발생할 수 있으므로, 정확한 정렬 로직이 필요했습니다.
이를 위해 임시 버퍼 공간을 두고 메시지를 일정 기간 적재한 뒤, 한 번에 정렬해 방출하는 구조를 설계했습니다.
즉, 일정량의 메시지를 모은 후 정렬을 수행하는 방식입니다.
@Component
class LiveMediaSubscriptionRepository {
companion object {
private val clientSseSubscription = ConcurrentHashMap<String, SseEmitter>()
/*
* 실시간 미디어 정보 버퍼 공간
*/
private val liveMediaQueue = ConcurrentLinkedQueue<LiveMediaMessageDto>()
private val latestLocationTimestampMap = ConcurrentHashMap<String, Long>()
}
fun storeLiveMediaMessages(liveMediaMessage: List<LiveMediaMessageDto>) {
liveMediaQueue.addAll(liveMediaMessage)
}
fun emitterStoredLiveMediaLocations() {
val liveMediaInfos = mutableListOf<LiveCreativeArtistLocationRepositoryDto>()
repeat(liveCreativeQueue.size) {
val poll = liveCreativeQueue.poll()
/*
* 미디어 아이디 별로 가장 최신 위치 정보만 전송
*/
if (poll != null && poll.mediaId != null && poll.timestamp != null && (latestLocationTimestampMap[poll.mediaId] ?: 0) <= poll.timestamp) {
latestLocationTimestampMap[poll.mediaId] = poll.timestamp
liveMediaInfos.add(poll)
}
}
if (liveMediaInfos.isNotEmpty()) {
/*
* 타임스탬프 기준으로 정렬하여 전송
*/
liveMediaInfos.sortBy { it -> it.timestamp }
runBlocking {
clientSseSubscription.entries
.map {
async {
sendEvent(
clientId = it.key,
id = RandomStringUtils.secureStrong().next(5),
name = "liveMapLocation",
data = liveMediaInfos
)
}
}.awaitAll()
}
}
}
}
private fun sendEvent(clientId: String, id: String, name: String, data: Any, reconnectTime: Long? = 1_000) {
val sseEmitter = clientSseSubscription[clientId] ?: return
try {
sseEmitter.send(
SseEmitter.event()
.id(id)
.name(name)
.data(data, MediaType.APPLICATION_JSON)
.reconnectTime(reconnectTime ?: 1_000L)
)
}
catch (e: Exception) {
logger.error("##### Error sending event to clientId: {}, error: {}", clientId, e.message)
}
}
}
초기에는 PriorityBlockingQueue를 사용해 삽입 시마다 자동 정렬되도록 고려했지만, 데이터가 빈번히 추가되는 환경에서는 매번 정렬 연산이 발생해 성능 저하가 우려되었습니다.
따라서 단순 적재만 수행하고, 필요할 때 한 번만 정렬하는 방식으로 변경했습니다.
이 과정에서 ConcurrentLinkedQueue를 사용해 멀티스레드 환경에서도 안전하게 메시지를 보관할 수 있도록 했습니다.
또한 30초 이상 지난 데이터는 무효 처리해 지연된 데이터가 사용자 화면에 표시되지 않도록 했으며, 마지막 전송 시각을 기록해 항상 최신 위치만 전송하도록 구현했습니다.
정리
이번 과정을 통해 단순히 기능을 구현하는 것을 넘어, 실시간 데이터 시스템에는 얼마나 많은 설계적 고민이 필요한지 직접 느낄 수 있었습니다.
처음에는 “그냥 Kafka 메시지를 받아서 브로드캐스트하면 되겠지”라고 생각했지만, 막상 여러 인스턴스 환경에서 순서 보장, 데이터 일관성, SSE 연결 관리 등 작은 부분 하나하나가 실시간성을 무너뜨릴 수 있는 요소들이었습니다.
Redis Pub/Sub을 통해 메시지를 공유하면서 “각 인스턴스가 하나의 시스템처럼 동작하도록 만드는 설계”의 중요성을 배웠고, 단순한 이벤트 전달 구조라도 데이터의 순서와 신뢰성을 지키는 일이 얼마나 중요한지 깨닫게 된 값진 경험이었습니다.