
트래픽 급격하게 몰려도 안정적으로 컨텐츠 조회수 카운팅 하기
서비스 요구사항 중 콘텐츠의 조회수 카운팅 기능을 개발하게 되었습니다.
이번 글에서는 “트래픽이 몰려도 안정적으로 카운팅 기능을 어떻게 설계할 수 있을까?” 라는 고민을 정리해보려 합니다.
사실 언뜻 보면 정말 단순한 기능 같아 보입니다. 하지만 조금만 깊게 들여다보면 고려해야 할 부분이 많은 기능이기도 합니다.

How YouTube Count Billions of Views in Milliseconds(Updated)
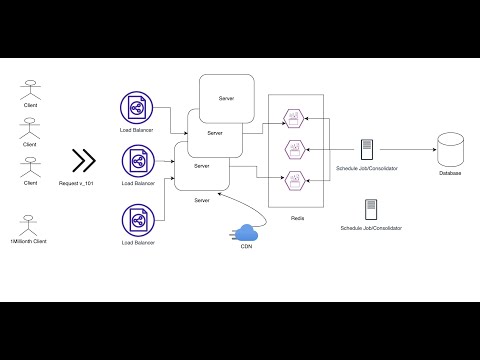
System Design View Counter for Videos
구글링만 해봐도 View Counting System Design(넷플릭스, 유튜브 등) 관련 자료를 쉽게 찾을 수 있습니다.
사소해 보이는 기능이라도, 짧은 응답 성능을 유지하기 위해서는 치열한 고민과 설계가 필요합니다.
단순 구현
첫 번째로 단순하게 조회수를 업데이트하는 로직을 떠올릴 수 있습니다.
class ContentService(
private repository: ContentJpaRepository
) {
fun findPost(id: Int): PostDto {
val post = repository.findPost(id)
repository.incrementViewCountById(id)
return post
}
}
interface ContentJpaRepository: JpaRepository<ContentEntity, Long> {
@Modifying
@Query("update ContentEntity c set c.viewCount = c.viewCount + 1 where c.id = :id")
@Transactional
fun incrementViewCountById(@Param("id") id: Long)
}
컨텐츠를 조회시 해당 컨텐츠의 조회수를 +1 업데이트 한다.
해당 로직은 단순히 조회수 카운팅만 본다면 문제가 없습니다. (물론 동시성 이슈는 별도) 하지만 트래픽이 몰릴 경우 큰 문제가 될 수 있습니다. 바로 데이터베이스 커넥션 자원 고갈 때문입니다.
커넥션 풀의 한계
Spring Boot에서 별도의 설정을 하지 않으면, DBCP 기본 커넥션 풀 사이즈는 10입니다.
즉 애플리케이션은 기본적으로 10개의 커넥션만 가지고 DB에 접근합니다.
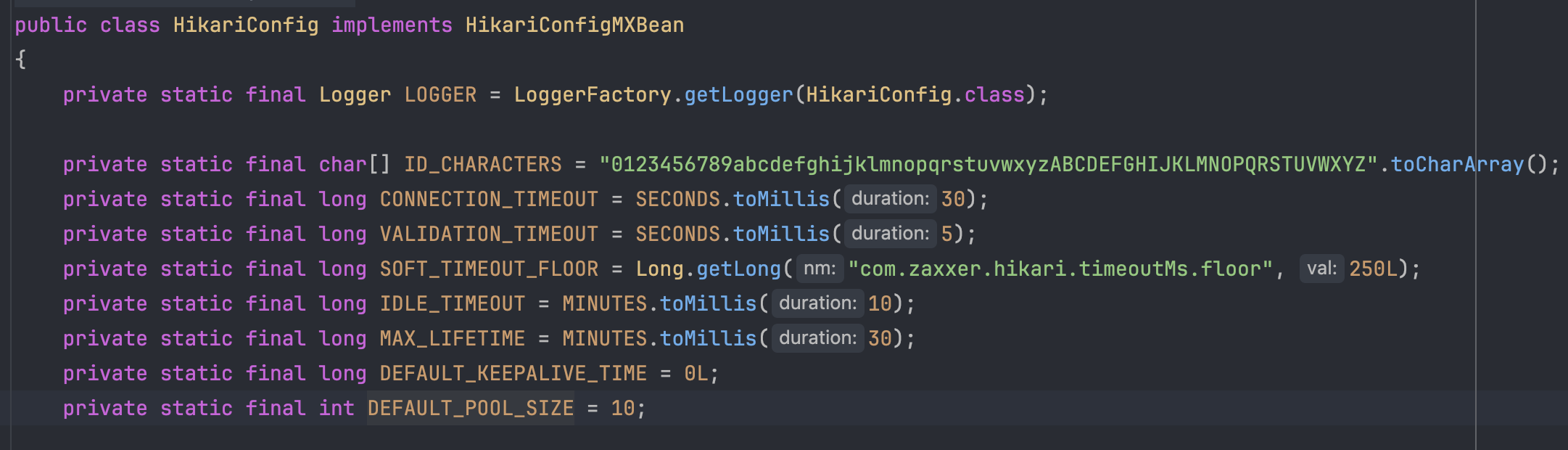
HikariConfig 클래스 내 기본
DEFAULT_POOL_SIZE값 (맨하단)
만약 특정 포스트가 갑자기 대박이 나서 트래픽이 몰린다면 어떻게 될까요? 포스트 조회 자체는 캐싱으로 처리한다고 해도, 조회수 업데이트는 매번 DB에 직접 쓰기 연산이 발생합니다.
그 결과 커넥션 풀이 빠르게 소진되고, 데이터를 필요로한 모든 기능들이 커넥션 획득을 기다려야 하는 상황이 벌어집니다.
정확히는 커넥션 부족 시
Max Connection Pool Size만큼 커넥션이 추가 생성되지만, Idle Timeout에 도달하면 제거됩니다.
흔히 드는 두 가지 생각
여기까지 읽으셨다면 아마 이런 생각을 하실 수 있습니다.
(저도 예전에 똑같이 했던 생각입니다 😂)
- DB 커넥션 수를 늘리면 되지 않을까?
- Redis에서 조회수 카운팅을 하면 되지 않을까?
1. DB 커넥션 수 늘리기
커넥션 수를 무작정 늘리면 해결될까요? 사실 그렇지 않습니다. 이유는 다음과 같습니다.
- DB 커넥션은 유한합니다. 내 서비스 때문에 커넥션을 늘리면, 같은 DB를 사용하는 다른 서비스가 장애를 겪을 수 있습니다.
- 커넥션은 지속 연결 상태입니다. 즉 세션 정보를 DB와 애플리케이션 양쪽 메모리에 유지해야 하므로 리소스 소모가 발생합니다.
- 동시에 많은 커넥션에서 쿼리가 실행되면, DB 엔진의 CPU·메모리·디스크 I/O 리소스를 두고 경쟁하게 됩니다. 이때 처리할 수 있는 리소스 이상으로 요청이 몰리면 쿼리가 대기열에 쌓이고, 결국 병목 현상이 발생합니다.
2. Redis로 카운팅 처리하기
Redis를 활용하면 어떨까요?
Redis는 키-값 저장소로 빠른 성능을 자랑하지만, 단순히 조회수 +1 용도로만 쓰기에는 레디스 부하 집중과 DB 동기화라는 문제가 남습니다.
성능적으로나 정합성 문제나 큰 이슈가 발생하지는 않겠지만, 단순 카운팅용으로는 다소 비효율적이라고 생각합니다.
안정적인 방법
제가 생각했을 때 안정적으로 조회수 카운팅하기 위한 핵심은 바로 효율적인 쓰기 연산 요청입니다.
보통 조회수는 반드시 실시간성이 필요한 데이터는 아닙니다.
따라서 조회수를 애플리케이션 인메모리에 카운팅하는 방식으로 설계할 수 있습니다.
조회수 카운팅에 대한 정책이나 세부 요구사항에 따라 설계 방식은 달라질 수 있습니다.
여기서는 단순히 카운팅만 한다는 전제하에 설명을 이어가겠습니다.
앱 인메모리에 저장하면 외부 저장소와의 I/O 작업이 발생하지 않기 때문에
DB 자원 고갈 이슈와 저장소 부하 문제를 상당 부분 해소할 수 있습니다.
class ContentInMemoryRepositoryImpl: ContentInMemoryRepository {
companion object {
private val viewCountMap = ConcurrentHashMap<Long, Long>()
}
override fun incrementViewCountById(id: Long) {
viewCountMap.merge(id, 1L, Long::plus)
}
}
incrementViewCountById함수를 통해 viewCountMap에 컨텐츠 id와 view count를 업데이트합니다.
멀티스레드 환경인 Spring Boot MVC에서 정적 메모리를 활용할 경우, 항상 동시성을 고려해야 합니다.
Java에서 제공하는 ConcurrentHashMap은 이러한 동시성 문제를 대비해 Map 내 데이터 조회와 값 변경 작업을 안전하게 수행할 수 있습니다.
인메모리에 조회수를 카운팅했다면 이제는 DB와의 동기화 작업이 필요합니다.
조회수를 준실시간으로 반영하기 위해서는 짧은 주기마다 DB에 동기화 작업을 진행하는 방식이 적합합니다.
예를 들어 5초마다 스케줄러를 실행해 조회수를 DB에 반영하는 식입니다.
@Component
class ContentScheduler(
private val service: ContentService
) {
/*
* 5초마다 조회수 동기화
*/
@Scheduled(fixedRate = 5_000)
fun synchronizeViewCount() {
service.synchronizeViewCount()
}
}
5초마다 디비 동기화 요청하는 스케줄러
@Service
class ContentService(
private val jpaRepository: ContentJpaRepository,
private val inMemoryRepository: ContentInMemoryRepository
) {
fun synchronizeViewCount() {
val viewCountMap = inMemoryRepository.copyViewCountMap()
viewCountMap.forEach { (id, viewCount) ->
jpaRepository.updateViewCount(id, viewCount)
}
}
}
inMemory 저장소에서 조회수 맵을 copy 하여 업데이트 한다.
@Repository
class ContentInMemoryRepositoryImpl: ContentInMemoryRepository {
companion object {
private val viewCountMap = ConcurrentHashMap<Long, Long>()
}
override fun copyViewCountMap(): Map<Long, Long> {
val copyMap = mutableMapOf<Long, Long>()
for (key in viewCountMap.keys) {
/*
* 조회수 카피된 컨텐츠 정보는 삭제한다.
*/
viewCountMap.remove(key)?.let {
copyMap[key] = it
}
}
return copyMap
}
}
InMemory 저장소
여기까지 인메모리에 조회수 카운팅하여 짧은 주기 스케줄링으로 DB 동기화하는 업데이트 부분입니다.
이 방식은 하나의 컨텐츠가 5초 동안 10번 조회되더라도,
기존처럼 10번의 쓰기 연산으로 커넥션을 점유하는 대신 단 한 번의 커넥션 점유로 업데이트할 수 있습니다.
즉, DB 커넥션 자원을 훨씬 효율적으로 활용할 수 있게 되는 것입니다.
물론 이 방식도 단점이 존재합니다.
1) ConcurrentHashMap 재해싱 이슈
2) 스케일아웃 환경에서 동시성 이슈
3) 애플리케이션 다운 시 정합성 이슈
1. ConcurrentHashMap 재해싱 이슈
첫 번째로, ConcurrentHashMap은 기본 capacity(16)와 load factor(0.75)를 가지고 있습니다.
맵의 크기가 임계치(capacity * load factor)에 도달하면 재해싱이 발생하고, 이 과정에서 지연이 생깁니다.
버킷 용량 2배수로 증가한 맵 추가되며 해당 맵으로 부터 데이터 이관하는 과정에서 지연이 발생합니다.
추가로 컨텐츠 수가 많아질수록 메모리 부담도 커지므로, 초기 용량을 적절히 계산해 설정하는 것이 중요합니다.
즉 재해싱 이슈로 인한 지연 이슈와 이를 고려한 메모리 부담을 고려해야합니다.
그래서 재해싱을 최대한 방지하기 위해 초기 capacity(버킷 용량) 설정이 중요합니다.
다만 5초마다 DB 동기화 과정에서 Map이 비워지므로, “5초 동안 얼마나 많은 컨텐츠가 조회될까?”를 고려한 capacity 설정을 하면 될것 같습니다.
재해싱 과정이 궁금하시다면 Load Factor and Rehashing, Load Factor in HashMap in Java with Examples 를 참고하시면 될 것 같습니다.
2. 스케일아웃 환경에서 조회수 업데이트시 동시성 이슈
두 번째 단점은 스케일아웃 환경에서의 동시성 문제입니다.
단일 애플리케이션에서만 조회수를 DB에 동기화한다면 큰 문제가 없지만,
애플리케이션 인스턴스가 여러 대로 확장될 경우 각 인스턴스가 동일한 스케줄러를 실행하게 됩니다.
이때 동일한 컨텐츠의 조회수를 동시에 업데이트하면서 충돌이 발생할 수 있습니다.
이를 해결하기 위한 방법으로는 낙관적 락(Optimistic Lock)과 비관적 락(Pessimistic Lock)이 있습니다.
비관적 락은 충돌이 날 것을 전제로 배타적(쓰기 연산을 사용한다 가정하에)으로 락을 걸어 다른 트랜잭션 접근을 막지만,
이 경우 조회 과정에서도 락 점유로 인해 사용자 응답 속도가 느려질 수 있습니다.
반면 낙관적 락은 충돌이 없을 것이라 가정하고 커밋 시점에만 충돌 여부를 확인하기 때문에
성능상 더 유리하고, 충돌이 발생하면 재시도로 해결할 수 있습니다.
낙관적 락을 사용할 경우, JPA에서는 엔티티에 @Version 어노테이션을 추가해 버전 정보를 관리할 수 있습니다.
처음 조회한 시점의 버전과 커밋 시점의 버전이 다르면 충돌이 발생했다고 판단하고,
이때 OptimisticLockingFailureException 예외가 발생합니다.
즉, 충돌이 감지되면 애플리케이션은 해당 작업을 재시도해야 합니다.
재시도는 단순히 try-catch 문과 반복문으로 구현할 수도 있지만, 이는 비즈니스 로직을 어지럽히는 방식입니다.
Spring에서는 @Retryable 같은 선언적 방법을 제공하므로 이를 활용하는 것이 좋습니다.
dependencies {
implementation("org.springframework.retry:spring-retry:2.0.12")
}
build.gradle
interface ContentJpaRepository: JpaRepository<ContentEntity, Long> {
/*
* 낙관적 락 예외가 발생할 경우 최대 5번까지 재시도합니다.
*/
@Retryable(
value = [OptimisticLockingFailureException::class],
maxAttempts = 5
)
@Modifying
@Query("update ContentEntity c set c.viewCount = :viewCount where c.id = :id")
@Transactional
fun updateViewCount(@Param("id") id: Long, @Param("viewCount") viewCount: Long)
}
JpaRepository
예를 들어, 조회수 업데이트 메서드에 @Retryable을 선언하면 충돌이 발생할 경우
지정된 횟수만큼 자동으로 재시도가 수행됩니다.
재시도 횟수는 보통 확장된 애플리케이션 인스턴스 수에 맞춰 설정하는 것이 적절합니다.
5개의 어플리케이션이 동일한 컨텐츠 조회수를 업데이트 할 시 모든 어플리케이션이 5번 이내에 업데이트 성공할 수 있기 때문입니다.
낙관적 락을 통해 동시성 이슈 해결과 업데이트 요청 과정에서 실패시 재시도 요청을 통해 정합성 문제를 해결할 수 있습니다.
3. 애플리케이션 다운시 조회수 정합성 이슈
세 번째 단점은 애플리케이션 다운 시 발생하는 정합성 문제입니다.
애플리케이션이 갑자기 종료되면 어플리케이션 인메모리에 저장되어 있던 조회수 데이터는 DB에 반영되지 못하고 사라집니다.
즉, 스케줄링 주기(예: 5초) 내에 발생한 조회수는 유실될 수 있습니다.
이 문제는 어플리케이션 인메모리에 저장해 주기적으로 동기화하는 방식의 근본적인 한계입니다.
따라서 완벽한 정합성을 보장하기는 어렵고, 일부 조회수가 반영되지 않을 수 있다는 점을 서비스 설계 시 반드시 인지해야 합니다.
이 부분은 결국 트레이드오프를 받아들이는 선택이라고 할 수 있습니다.
결론
성능 최적화를 위한 설계 의도는 앞서 말씀드린 것처럼 효율적인 쓰기 연산 요청입니다.
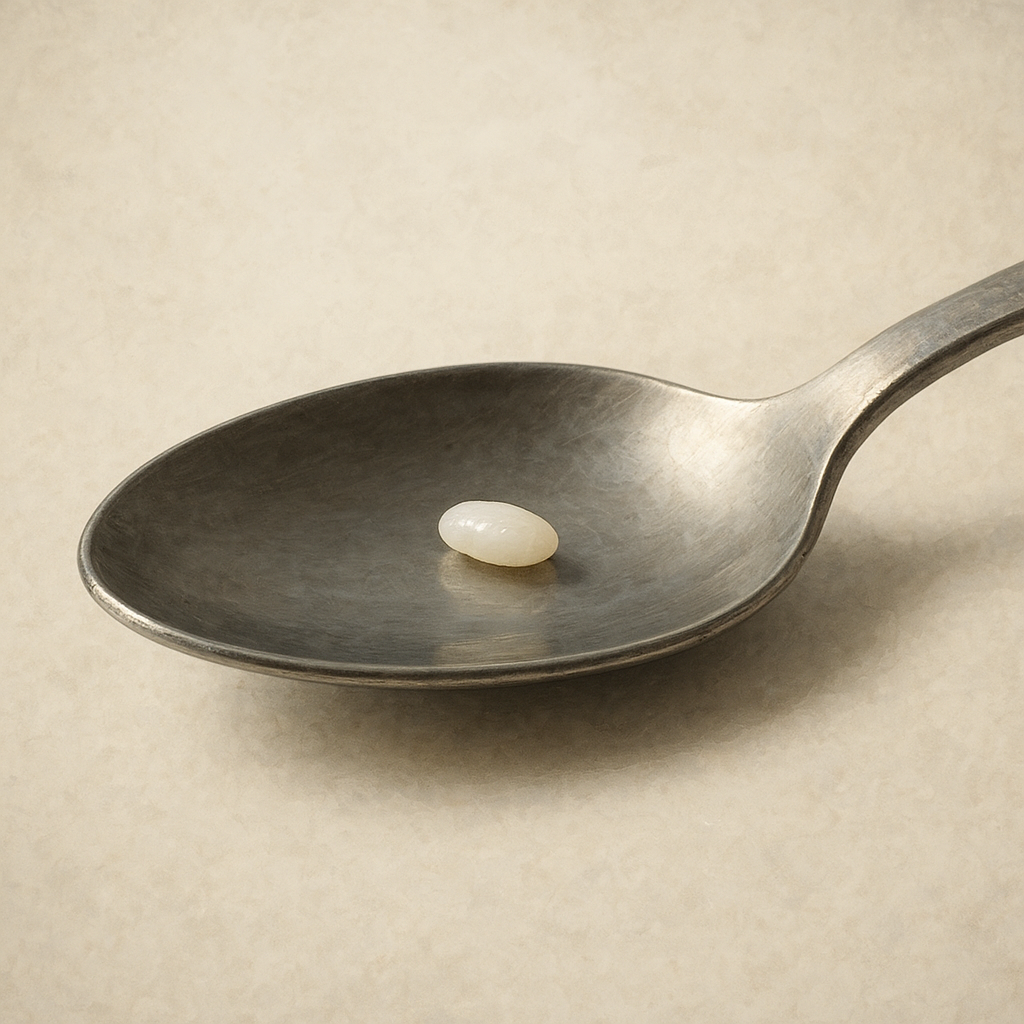 |
 |
|---|---|
| 숟가락에 쌀 한 톨 | 숟가락에 쌀 가득 |
한 톨씩 여러 번 옮기는 것보다, 한 번에 가득 옮기는 것이 훨씬 효율적이지 않을까요?
즉, 여러 번의 쓰기 요청을 줄여 다른 기능으로 성능 이슈가 전파되지 않도록 하는 것이
안정적인 서비스를 제공하는 핵심이라고 생각합니다.
커넥션은 소중하니까요
다만 앞서 설명드린 설계 방식에서는 데이터 정합성이 맞지 않는 이슈가 발생할 수 있습니다.
“정합성이 맞지 않으면 바로 카운팅 업데이트하는 게 맞지 않아?”라는 의문이 생길 수 있고, 이 부분에서 고민이 생깁니다.
이 점이 바로 트레이드오프라 생각됩니다. 안정적인 서비스를 제공하는 대신 완벽한 정합성은 포기할 것인지,
아니면 완벽한 정합성을 보장하는 대신 성능 이슈를 감안할 것인지에 대한 선택이 필요한 것이죠.
따라서 우리는 해당 데이터가 반드시 정합성을 요구하는 데이터인지 명확히 인지할 필요가 있습니다.
이 논의는 제품 요구사항에 따라 달라질 수 있으며, 충분한 논의 후 결정하는 것이 바람직합니다.
추가로 중복 조회수 감지나 조회 로깅까지 고려한다면,
“처음부터 Kafka를 도입해서 조회수를 처리하면 되지 않을까?”라는 질문도 나올 수 있습니다.
물론 좋은 방법일 수 있지만, 시스템 관리 복잡도가 크게 올라갑니다.
만약 조회수 카운팅에 대한 세부 요구사항이 명확하지 않다면 섣불리 Kafka 도입은 지양해야 한다고 생각합니다.
적용한다면 토픽 적재 비용과 최적화 방법까지 함께 고민해야 할 것입니다.
또 누군가에겐 작은 트래픽에 괜한 유난이라는 말이 나올 수도 있습니다.
물론 유튜브 사례처럼 모든 서비스가 대용량 트래픽을 경험하며
조회수만 전담하는 별도 시스템을 설계하면 좋겠지만, 현실적으로는 쉽지 않습니다.
불필요한 오버 엔지니어링이 될 수 있으니까요.
저는 그렇다고 해서 단순히 안일하게 처리할 수도 없었습니다.
그래서 나름대로 깊이 고민했던 내용을 이렇게 글로 정리해 보았습니다.
긴 글 읽어주셔서 감사합니다 🙏